
A Cybersecurity specialist, a cryptographic engineer, a cryptographer and a quantum communications researcher walk into a room.
Tan Teik Guan
Tan Teik Guan
When I started implementing ML-KEM (Module-Lattice-based Key-Encapsulation Mechanism) for a cryptographic audit engine, I expected it to behave like a fairly predictable piece of cryptographic plumbing - but it was deeper than that.
Digging deeper, I ended up inside a system that feels like a mix of clean lattice mathematics and deliberate paranoia. ML-KEM doesn’t just protect secrets—it assumes every input might be malicious, and then very carefully avoids telling you when or how an attack failed.
At a surface level, it still looks like a standard key encapsulation mechanism: one party produces a ciphertext, the other decapsulates it to recover a shared secret. But once you start looking at adversarial behavior, it stops behaving like a simple lock-and-key system and starts behaving like a protocol designed to give attackers as little information as physically possible.
This article breaks down how that design shows up internally, and what changes when you stress-test its assumptions under manipulation.
ML-KEM is designed to achieve IND-CCA2 security (Indistinguishability under Adaptive Chosen-Ciphertext Attack). In simple terms, this means that even if an attacker can request decapsulations of chosen ciphertexts (with the exception of a single challenge ciphertext), they still cannot learn anything useful about the underlying shared secret.
This is significantly stronger than earlier security notions such as IND-CPA and IND-CCA1:
| IND-CPA | The attacker can obtain encryptions of chosen plaintexts but has no access to decryption behavior in the security model |
| IND-CCA1 | The attacker may observe decryption behavior, but only prior to the challenge phase |
| IND-CCA2 | Removes that restriction entirely, allowing queries both before and after the challenge—except for the challenge itself |
To withstand this level of adversarial access, ML-KEM uses the Fujisaki–Okamoto (FO) transform. Before explaining its implementation, let’s understand the structure of the parameters used for decapsulation: the decapsulation key and the ciphertext
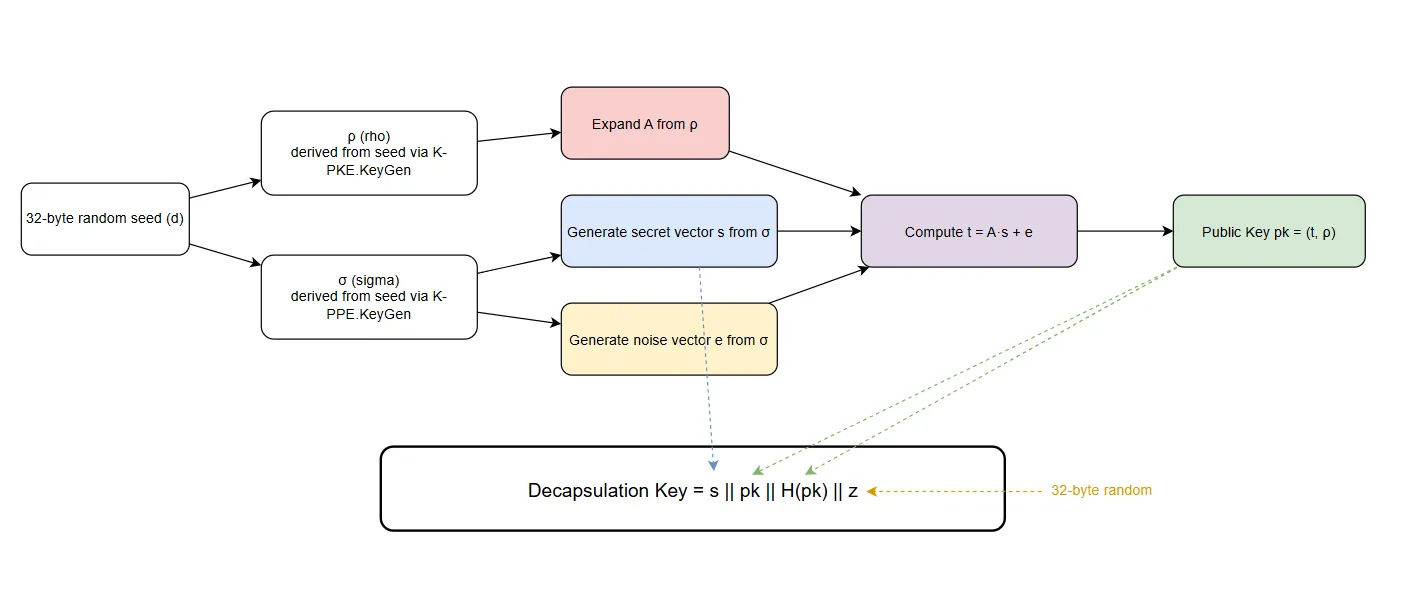
The ML-KEM decapsulation key (private key) is not a single object but a structured bundle of arithmetic operations with matrices, vectors and jitter/noise.
The diagram below outlines the steps taken to derive a decapsulation key from a random 32-byte seed:
The table below shows the different ML-KEM parameters and their breakdowns:
| Parameter Sets | secret vector s (bytes) | public key (bytes) | hash of public key (bytes) | random z (bytes) | Total Length of Decapsulation Key (bytes) |
| ML-KEM-512 | 768 | 800 | 32 | 32 | 1632 |
| ML-KEM-768 | 1152 | 1184 | 32 | 32 | 2400 |
| ML-KEM-1024 | 1536 | 1568 | 32 | 32 | 3168 |
Conceptually, the decapsulation key is split into components that allow:
● Efficient reconstruction of secret structure
● Verification of ciphertext correctness
● Re-encryption during decapsulation for consistency checking
Therefore, we understand that ML-KEM does not simply “decrypt” ciphertexts - it validates them as well.
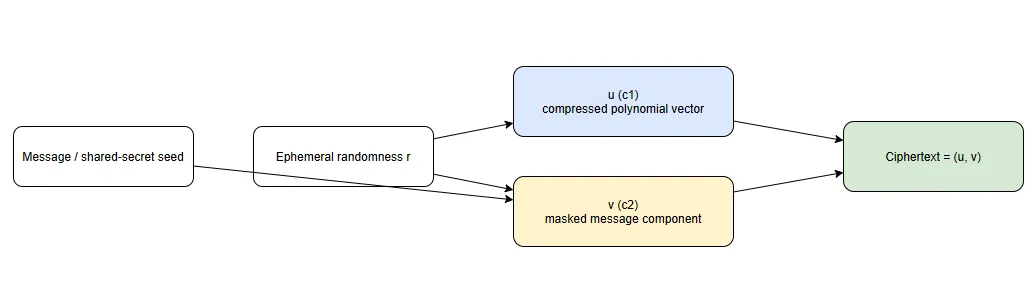
The ML-KEM ciphertext typically consists of two main parts:
● u (or c1): A compressed or encoded polynomial vector derived from the public matrix and ephemeral randomness
● v (or c2): The masked message component containing the encapsulated shared secret material
| Parameter Sets | u (bytes) | v (bytes) | Total Length of Ciphertext (bytes) |
| ML-KEM-512 | 640 | 128 | 768 |
| ML-KEM-768 | 960 | 128 | 1088 |
| ML-KEM-1024 | 1408 | 160 | 1568 |
Depending on parameter sets, these components are compressed to reduce bandwidth, meaning even small bit flips can significantly alter decapsulation behavior.
The ciphertext is tightly bound to the public key via randomness derived from hashing mechanisms, ensuring non-malleability under normal conditions.
Now that the structures of the parameters have been established, back to the FO transform. The Fujisaki-Okamoto (FO) Transform is cryptographic transformation that takes a symmetric key encryption and a public-key encryptions scheme to create a hybrid scheme that’s secure against chosen-ciphertext attacks.
It tightly couples encryption and decryption and adds consistency checking to ensure that malformed or tampered ciphertexts do not leak any useful information. So how is this implemented in ML-KEM?
When an ML-KEM decryption fails, it does not output “decryption has failed” - instead, it still produces a shared secret as the output, as if decryption was successful. However, this is deceit in plain sight. The shared secret is not the actual output K’, but a pseudo-random shared secret K⁻ generated using the FO transform, to throw off users with ill-intentions.
These are the steps followed to derive the pseudo-random shared secret K⁻ through a multi-step FO transform:
If they match:
● The decapsulation succeeds
● The shared secret is derived by hashing the recovered message and ciphertext
| Decapsulation Result | Shared Secret Derivation Formula |
| Success, c = c’ | K’ = SHA3-512 (m’||h) where, m’ → the decapsulated message h → the hash of the public key from the decapsulation key |
If they do not match:
● The output is replaced with a pseudo-random value derived from the decapsulation key and ciphertext hash
| Decapsulation Result | Shared Secret Derivation Formula |
| Failure, c != c’ | K⁻ = SHAKE256 (z||c, 32) where, z → the 32-byte random at the end of the decapsulation key c → provided ciphertext 32 → requesting a 32-byte output from the SHAKE256 function |
This fallback behavior is critical and essential in preventing attackers from learning whether decryption succeeded or failed, eliminating oracle leakage.
Working on creating an audit engine for post-Quantum algorithms such as ML-KEM, naturally I became curious about the malleability of the IND-CCA2 + FO transform implementation.
Once you start actively tampering with ML-KEM inputs, the system behaves less like a cryptographic algorithm and more like a carefully controlled failure machine. The important thing to notice is that ML-KEM does not “partially fail” in any meaningful sense — it either produces the correct shared secret K’ or it silently collapses into a pseudo-random shared secret K⁻.
What makes this interesting is that both K’ and K⁻ are always computable in principle, but only one is ever revealed depending on verification.
I wanted to assume the point of view of a hacker and see how much information I can extract from understanding the decapsulation behavior and the different pseudo-random shared secrets produced.
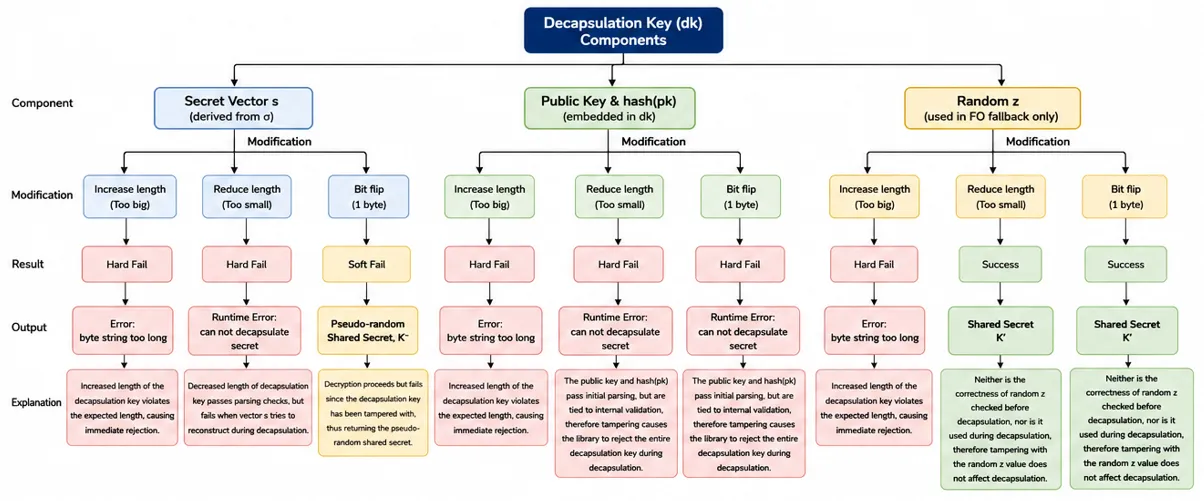
If you start modifying the different components of the decapsulation key, it depicts various behaviors. For thorough, all-rounded testing, each of the 4 decapsulation key components were modified by increasing its length, decreasing its length, as well as tampered with by performing a bit flip, given that the ciphertext remains intact:
Key note:
→ There are stringent cryptographic checks on the decapsulation key that tampering with any of its components, except random z, does not perform a decapsulation
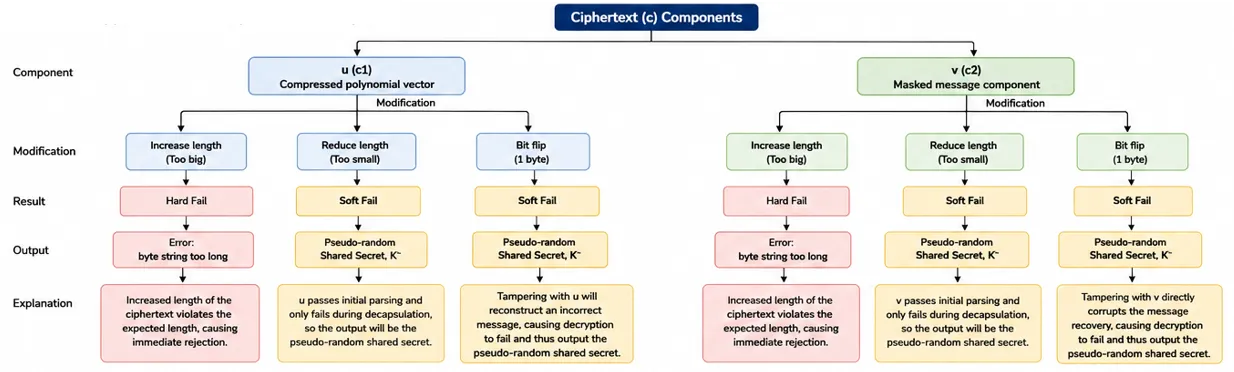
Ciphertext is where behavior becomes more dynamic. Like the decapsulation key, each of the 2 ciphertext components, u and v, were modified by increasing its length, decreasing its length, as well as tampered with by performing a bit flip, given that the decapsulation key remains intact:
Key note:
→ Any change to ciphertext c produces a different K⁻ because K⁻ depends directly on c
The results identify 3 different failure levels in the ML-KEM implementation:
| Failure Type | Example | Result |
| Serialization Failure | Length too long | Hard Fail |
| Structural Decode Failure | Malformed Encoding | Hard Fail |
| Cryptographic Consistency Failure | Wrong Math | Soft Fail |
Only the last category reaches the pseudo-random shared secret. This means that the FO transform only protects failures that occur after the ciphertext and keys are accepted as structurally valid inputs.
One of the more interesting observations from these tamper tests is that not all components of the decapsulation key contribute equally to the final shared secret output. Tampering with critical reconstruction components such as the embedded public key, or h(pk) typically disrupts decapsulation and forces the implementation into the FO fallback path.
In contrast, the random value z behaves differently: because it is only used after a failed decapsulation and a FO transform to derive the pseudo-random fallback secret K⁻, modifying z alone does not affect successful decapsulation or the correctly derived shared secret K’.
This creates a subtle separation between components involved in normal cryptographic recovery and components reserved purely for failure-handling behavior.
ML-KEM is not just a lattice-based encryption mechanism - it is a carefully engineered system that enforces strong security guarantees even under active manipulation. Its reliance on structured keys, compressed ciphertexts, and the Fujisaki–Okamoto transform ensures that tampering does not produce meaningful information leaks.
From an implementation perspective, the most important lesson is that correctness checks are not optional - they are part of the security proof. Every failure path is intentionally designed to be indistinguishable from success.
Understanding these internal behaviors is essential when building audit tools, side-channel resistant implementations, or analyzing post-quantum cryptographic systems in adversarial environments.
Author
Praveenaa is an Associate Software Engineer at pQCee. Fascinated by the shift toward quantum-safe cybersecurity, she works on advancing solutions that anticipate tomorrow’s threats — fuelled by her love for representing Singapore in Kabaddi and slowly sipping iced coffee.
A Cybersecurity specialist, a cryptographic engineer, a cryptographer and a quantum communications researcher walk into a room.
Tan Teik Guan
Don't have an account? We will create one for you.
Enter the OTP send to
in seconds. Check your spam folder if you can't find email from us.
Valid email is required for further communications